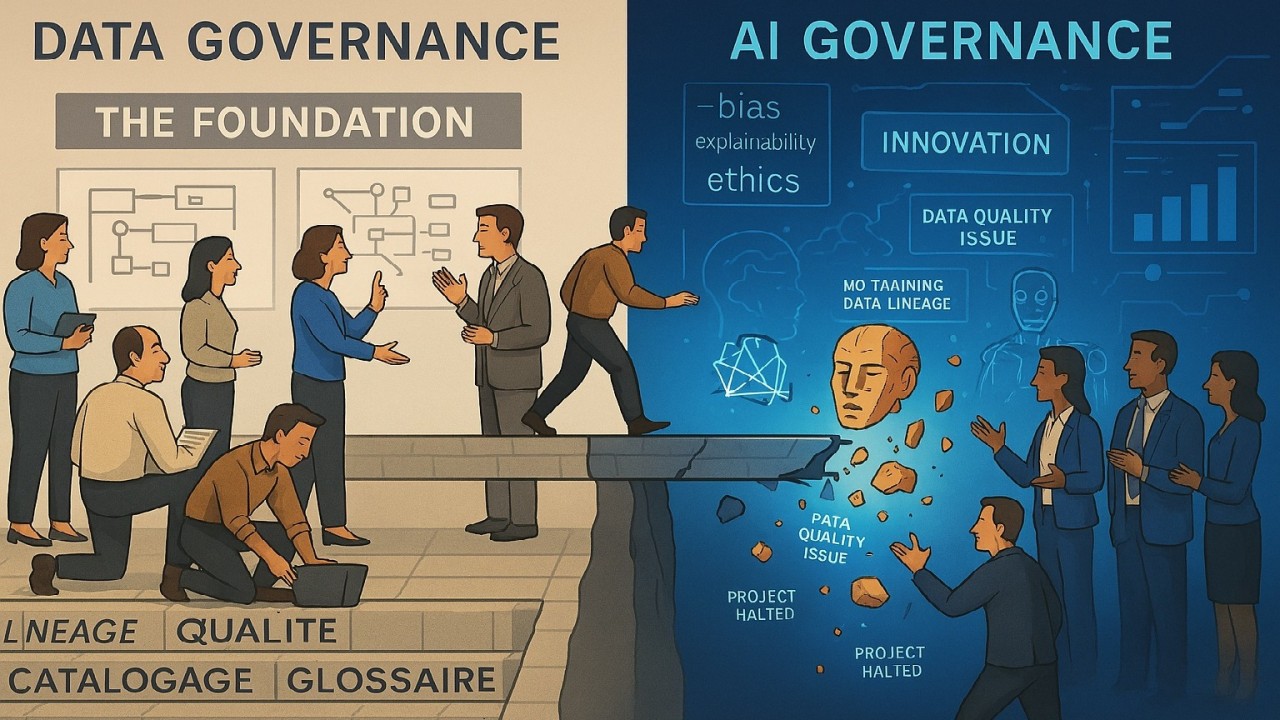
Dans le framework de gouvernance de l’IA que nous avons déjà partagé avec vous (voir schéma ci-dessous), la gouvernance de l’intelligence artificielle s’appuie sur trois sujets, les données, les modèles et les usages.

Le sujet des modèles et celui des usages est propre à la gouvernance de l’IA, mais celui des données doit être aligné avec la gouvernance des données.
Aligné, car il y a un recouvrement partiel. Seules les données utilisées dans les modèles d’IA, en entrée tout comme en sortie, font partie de la gouvernance de l’IA. Mais leur démarche de gouvernance ne peut être totalement déconnectée des efforts menés en matière de gouvernance des données, en particulier autour des trois axes de cette dernière : connaissance, qualité, et conformité.
Tentons de détailler ici les composants de cet alignement.
Le catalogue de données : outil incontournable
Seules sont concernées par la gouvernance de l’IA les données utilisées par les projets en question, mais quel que soit le type d’IA : symbolique (systèmes experts), connexionniste (apprentissage machine et profond) et bien sur les projets d’IA générative. Quel que soit le type de données également, structurées ou non structurées. Et quels qu’en soient les usages futurs.
L’outil charnière entre la gouvernance des données et de l’IA est le catalogue des données. Sans ce catalogue, comment identifier quels modèles d’IA utilisent quelles données ? Et quelles données sont utilisées dans quels modèles d’IA ?
C’est non seulement une bonne pratique, mais une exigence règlementaire : toute donnée utilisée dans un modèle d’IA doit être référencée dans le catalogue de données.
Les éléments indispensables de ce référencement seront : les caractéristiques techniques de la donnée, sa définition, son référent métier, sa classification, la mesure de son niveau de qualité, sa conformité ; et bien sûr chaque fiche de donnée sera connectée au catalogue des modèles d’IA, permettant de naviguer de manière bidirectionnelle entre les données et les modèles. Ces bonnes pratiques sont par ailleurs obligatoires dans le cadre des conformités RGPD et IA Act.
Gouvernance : qui est responsable de quoi ?
Chacun a sa partition à jouer :
- Le responsable de la gouvernance des données définit le métamodèle du catalogue des données ;
- Le responsable de la gouvernance de l’IA définit le métamodèle du catalogue des modèles d’IA ;
- Les référents métier ont en charge la création des fiches pour les données utilisées dans les modèles ;
- Les chefs de projet IA ont en charge la création des fiches de chacun des modèles ;
- Le data & AI steward (avec l’aide du DPO) contrôle le respect de ces règles de gouvernance et reporte éventuellement les incidents constatés au comité de gouvernance ;
Les Data Contract, un moyen pour faciliter la qualité et la conformité des données pour l’IA
En matière de données d’entrainement, des indicateurs particuliers, propres à l’IA, devront être ajoutés aux critères de qualité et de conformité. Ils ne sont pas inclus dans la gouvernance habituelle des données, mais prennent leur sens une fois celles-ci utilisées par des modèles d’IA.
Nous parlons ici de la détection des biais, des discriminations, des inégalités, qui ne sont pas propres à une donnée, mais à un ensemble de données.
Ainsi le catalogue des données s’enrichit avec l’IA, de nouvelles dimensions de contrôle de la qualité.
L’utilisation de data contracts entre les applications sources et les modèles d’IA permettront de prévoir ces contrôles de qualité, et d’alimenter automatiquement les outils tels que les catalogues, les outils de transformation de données, et les outils de suivi de la conformité. Le choix d’un modèle ouvert et standardisé de data contract tel que Open Data Contract Standard (ODCS) défini par Bitol – Fondation Linux, est recommandé.
L’historisation de la donnée pour faciliter l’auditabilité des modèles et la réutilisation pour de nouveaux usages
Nous avons vu ci-dessus comment les catalogues de données et de modèles travaillent ensemble et se connectent. Le catalogue des modèles contiendra de nombreux autres indicateurs permettant aux chefs de projet et aux data stewards de suivre la justesse de leurs réponses, leur dérive, de détecter d’éventuelles hallucinations, etc. Ce catalogue des modèles est indépendant de la gouvernance des données, mais l’ensemble doit être aligné.
Entre les catalogues (des données, des modèles, technique, métier…) la règle est claire : aucune information ne doit être saisie en double entre deux catalogues, un lien doit toujours être privilégié.
Alors que la gouvernance des données se concentre sur les données en entrée, celle de l’IA devra également couvrir les données en sortie des modèles. L’IA générative, tout comme l’apprentissage profond sont des outils complexes à auditer sous l’angle de leur conformité. Bien souvent, une traçabilité des questions et réponses doit être prévue, afin d’analyser les réponses à posteriori. Historiser les prompts et les réponses obtenues sera l’unique moyen de constater des dérives, des a priori, des inégalités. Ajouter les données en sortie des modèles dans le catalogue de données est une option, et celle-ci se révélera payante sur le long terme, car elle facilitera les audits et contrôles (internes et externes), mais elle permettra surtout une meilleure réutilisation des données dans d’autres modèles.
Pour suivre toutes ces métadonnées de gouvernance, un cockpit de pilotage est fortement conseillé. Il sera consulté par le comité de gouvernance pour comprendre les sujets sur lesquels il doit se prononcer. Ce cockpit, facilitera l’alignement et le passage de la gouvernance de l’IA à celle des données et inversement.
Il n’y a pas deux gouvernances, une de l’IA et une des données, mais une gouvernance globale, dont ses deux composantes doivent être parfaitement alignées.
